Welcome to MIT HAN Lab! We specialize in efficient generative AI, including large language models (LLMs), multi-modal models (VLMs/VLAs), and diffusion models. Today’s foundation models are remarkably powerful but prohibitively costly in terms of computation, energy, and scalability. At MIT HAN Lab, we integrate algorithm–system co-design to push the frontier of AI efficiency and performance. Our research spans the entire AI stack—from pre-training and post-training to model compression and deployment—bridging fundamental breakthroughs with real-world applications. By rethinking how AI is designed with GPU efficiency in mind, we aim to make generative AI faster, greener, and more accessible.
PI: Prof. Song Han
Alumni: Ji Lin (OpenAI), Hanrui Wang (Co-Founder @Eigen AI, acquired by Nebius), Zhijian Liu (Assistant professor @UCSD), Han Cai (NVIDIA Research), Haotian Tang (Google Deepmind->Meta), Yujun Lin (NVIDIA Research), Wei-Chen Wang (Co-Founder @Eigen AI, acquired by Nebius), Wei-Ming Chen (NVIDIA).
Accelerating LLM and Generative AI [slides]:





Kernel Design Agents (KDA) achieves 1st place in the MoE Track, 2nd place in the DSA Track, and 3rd place in the GDN Track at the MLSys 2026 FlashInfer Full-Agent Track!
HART has been highlighted by MIT news: AI tool generates high-quality images faster than state-of-the-art approaches!
🔥⚡ We release TinyChat 2.0, the latest version with significant advancements in prefilling speed of Edge LLMs and VLMs, 1.5-1.7x faster than the previous version of TinyChat. Please refer to our blog for more details.
DistriFusion is integrated in NVIDIA's TensorRT-LLM for distributed inference on high-resolution image generation.
🔥 NVIDIA TensorRT-LLM, AMD, Google Vertex AI, Amazon Sagemaker, Intel Neural Compressor, FastChat, vLLM, HuggingFace TGI, and LMDeploy adopt AWQ to improve LLM serving efficiency. Our AWQ models on HuggingFace has received over 6 million downloads.
Congrats on graduation! Cheers on the next move: Zhijian Liu: assistant professor at UCSD, Hanrui Wang: assistant professor at UCLA, Ji Lin: OpenAI, Han Cai: NVIDIA Research, Wei-Chen Wang (postdoc): Amazon, Wei-Ming Chen (postdoc): NVIDIA.
We show SmoothQuant can enable W8A8 quantization for Llama-1/2, Falcon, Mistral, and Mixtral models with negligible loss.
We supported VILA Vision Languague Models in AWQ & TinyChat! Check our latest demos with multi-image inputs!
StreamingLLM is integrated by HPC-AI Tech SwiftInfer to support infinite input length for LLM inference.
StreamingLLM is integrated by CMU, UW, and OctoAI, enabling endless and efficient LLM generation on iPhone!
Congrats Ji Lin completed and defended his PhD thesis: "Efficient Deep Learning Computing: From TinyML to Large Language Model". Ji joined OpenAI after graduation.
AWQ is integrate by NVIDIA TensorRT-LLM, can fit Falcon-180B on a single H200GPU with INT4 AWQ, and 6.7x faster Llama-70B over A100.
🔥 AWQ is now integrated natively in Hugging Face transformers through from_pretrained. You can either load quantized models from the Hub or your own HF quantized models.
Attention Sinks, an library from community enables StreamingLLM on more Huggingface LLMs. blog.

Vision-Language-Action models (VLAs) are becoming increasingly capable across diverse robotic tasks. However, their real-world deployment remains slow and inefficient: demonstration videos are often sped up by 5-10x to appear smooth, with noticeable action stalls and delayed reactions to environmental changes. Asynchronous inference offers a promising solution to achieve continuous and low-latency control by enabling robots to execute actions and perform inference simultaneously. However, because the robot and environment continue to evolve during inference, a temporal misalignment arises between the prediction and execution intervals. This leads to significant action instability, while existing methods either degrade accuracy or introduce runtime overhead to mitigate it. We propose VLASH, a general asynchronous inference framework for VLAs that delivers smooth, accurate, and fast reaction control without additional overhead or architectural changes. VLASH estimates the future execution-time state by rolling the robot state forward with the previously generated action chunk, thereby bridging the gap between prediction and execution. Experiments show that VLASH achieves up to 2.03x speedup and reduces reaction latency by up to 17.4x compared to synchronous inference while fully preserving the original accuracy. Moreover, it empowers VLAs to handle fast-reaction, high-precision tasks such as playing ping-pong and playing whack-a-mole, where traditional synchronous inference fails.
VLASH is a general asynchronous inference framework for VLAs that delivers smooth, accurate, and low-latency control with no overhead or architectural changes. By rolling the robot state forward with the previous action chunk, it achieves up to 2.03× speedup and 17.4× lower reaction latency while fully preserving accuracy.
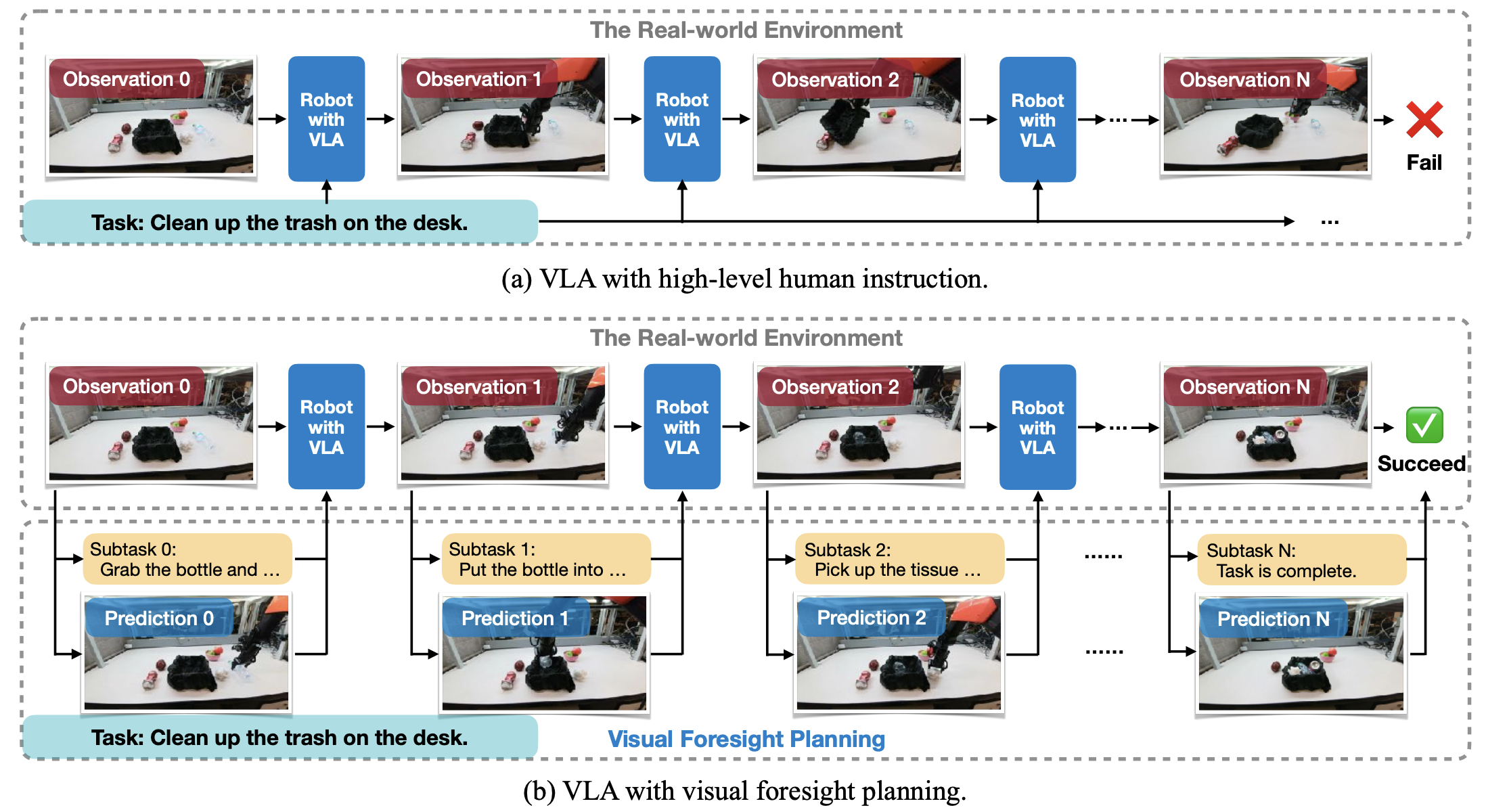
Vision-Language-Action (VLA) models convert high-level language instructions into concrete, executable actions, a task that is especially challenging in open-world environments. We present Visual Foresight Planning (ForeAct), a general and efficient planner that guides a VLA step-bystep using imagined future observations and subtask descriptions. With an imagined future observation, the VLA can focus on visuo-motor inference rather than high-level semantic reasoning, leading to improved accuracy and generalization. Our planner comprises a highly efficient foresight image generation module that predicts a high-quality 640×480 future observation from the current visual input and language instruction within only 0.33s on an H100 GPU, together with a vision-language model that reasons over the task and produces subtask descriptions for both the generator and the VLA. Importantly, state-of-the-art VLAs can integrate our planner seamlessly by simply augmenting their visual inputs, without any architectural modification. The foresight generator is pretrained on over 1 million multi-task, cross-embodiment episodes, enabling it to learn robust embodied dynamics. We evaluate our framework on a benchmark that consists of 11 diverse, multi-step realworld tasks. It achieves an average success rate of 87.4%, demonstrating a +40.9% absolute improvement over the π0 baseline (46.5%) and a +30.3% absolute improvement over π0 augmented with textual subtask guidance (57.1%).
ForeAct is a plug-and-play visual foresight planner that enables state-of-the-art VLAs to anticipate high-fidelity future observations for improved decision-making, generating 640×480 predictions in just 0.33s on a single H100 GPU without any architectural changes.
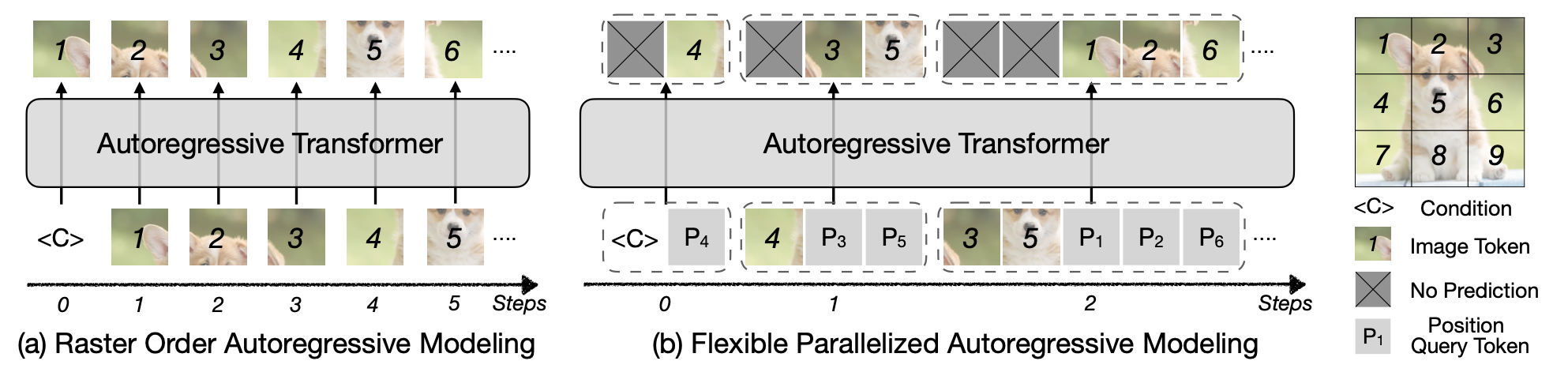
We present Locality-aware Parallel Decoding (LPD) to accelerate autoregressive image generation. Traditional autoregressive image generation relies on next-patch prediction, a memory-bound process that leads to high latency. Existing works have tried to parallelize next-patch prediction by shifting to multi-patch prediction to accelerate the process, but only achieved limited parallelization. To achieve high parallelization while maintaining generation quality, we introduce two key techniques: (1) Flexible Parallelized Autoregressive Modeling, a novel architecture that enables arbitrary generation ordering and degrees of parallelization. It uses learnable position query tokens to guide generation at target positions while ensuring mutual visibility among concurrently generated tokens for consistent parallel decoding. (2) Locality-aware Generation Ordering, a novel schedule that forms groups to minimize intra-group dependencies and maximize contextual support, enhancing generation quality. With these designs, we reduce the generation steps from 256 to 20 (256×256 res.) and 1024 to 48 (512×512 res.) without compromising quality on the ImageNet class-conditional generation, and achieving at least 3.4× lower latency than previous parallelized autoregressive models.
We introduce Locality-aware Parallel Decoding to accelerate autoregressive image generation and achieve 13× faster than traditional AR models and at least 3.4× faster than previous parallelized AR models.
Vision-language models (VLMs) could power real-time assistants and autonomous agents, but they face a critical challenge: understanding near-infinite video streams without escalating latency and memory usage. Processing entire videos with full attention leads to quadratic computational costs and poor performance on long videos. Meanwhile, simple sliding window methods are also flawed, as they either break coherence or suffer from high latency due to redundant recomputation. In this paper, we introduce StreamingVLM, a model designed for real-time, stable understanding of infinite visual input. Our approach is a unified framework that aligns training with streaming inference. During inference, we maintain a compact KV cache by reusing states of attention sinks, a short window of recent vision tokens, and a long window of recent text tokens. This streaming ability is instilled via a simple supervised fine-tuning (SFT) strategy that applies full attention on short, overlapped video chunks, which effectively mimics the inference-time attention pattern without training on prohibitively long contexts. For evaluation, we build Inf-Streams-Eval, a new benchmark with videos averaging over two hours that requires dense, per-second alignment between frames and text. On Inf-Streams-Eval, StreamingVLM achieves a 66.18% win rate against GPT-4o mini and maintains stable, real-time performance at up to 8 FPS on a single NVIDIA H100.
StreamingVLM enables real-time understanding of infinite videos with low, stable latency. By aligning training on overlapped video chunks with an efficient KV cache, it runs at 8 FPS on a single H100. It achieves a 66.18% win rate vs. GPT-4o mini on a new benchmark with videos averaging over 2 hours long.
We actively collaborate with industry partners on efficient AI, model compression and acceleration. Our research has influenced and landed in many industrial products: Intel OpenVino, Intel Neural Network Distiller, Intel Neural Compressor, Apple Neural Engine, NVIDIA Sparse Tensor Core, NVIDIA TensorRT LLM, AMD-Xilinx Vitis AI, Qualcomm AI Model Efficiency Toolkit (AIMET), Amazon AutoGluon, Facebook PyTorch, Microsoft NNI, SONY Neural Architecture Search Library, SONY Model Compression Toolkit, ADI MAX78000/MAX78002 Model Training and Synthesis Tool.






















