SmoothQuant is adopted by AMD Instinct MI300X using Composable Kernel.
We show SmoothQuant can enable W8A8 quantization for Llama-1/2, Falcon, Mistral, and Mixtral models with negligible loss.
SmoothQuant is adopted by Microsoft ONNX Runtime.
SmoothQuant is adopted by NVIDIA TensorRT-LLM.
SmoothQuant is adopted by Amazon SageMaker.
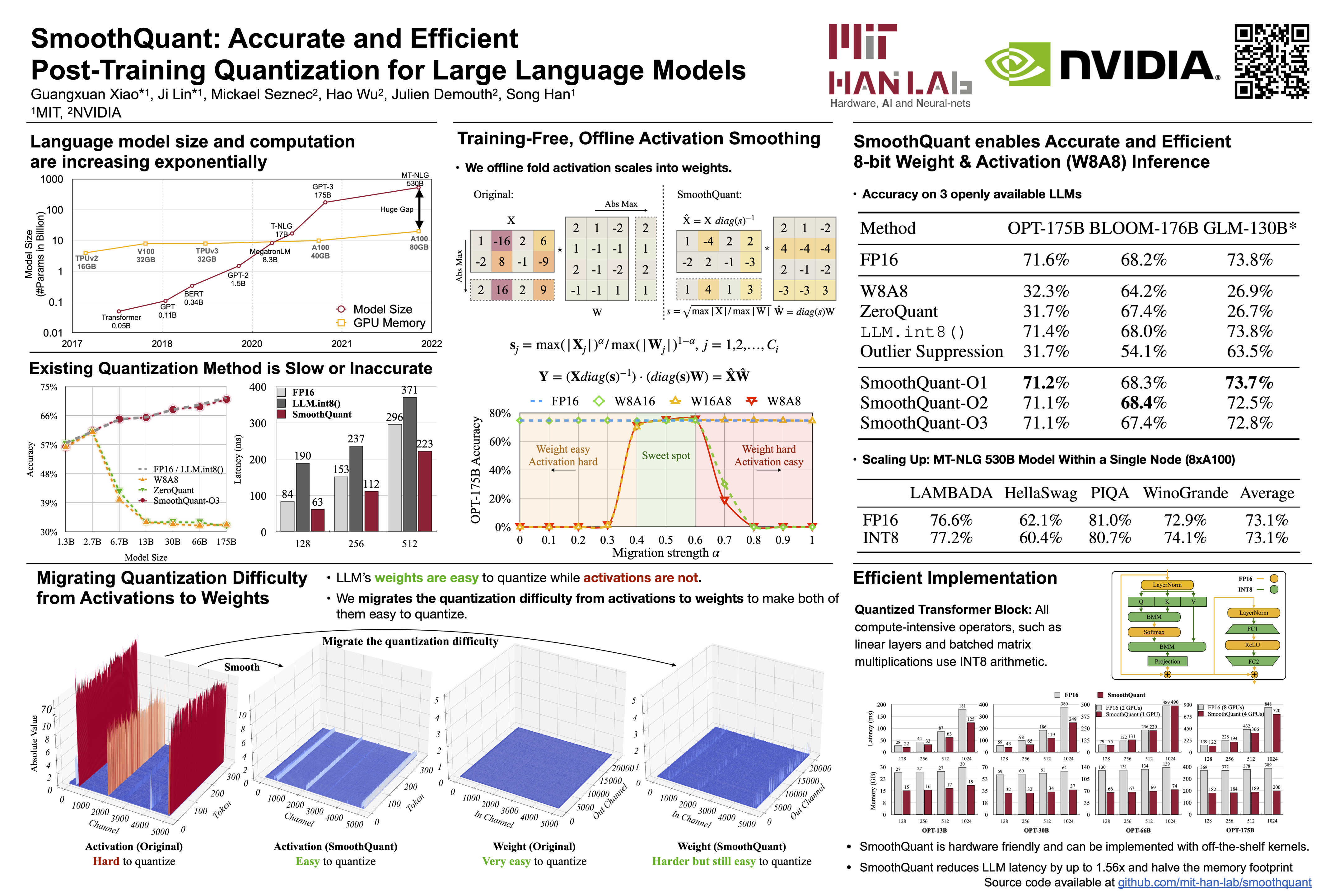
Large language models (LLMs) show excellent performance but are compute- and memory-intensive. Quantization can reduce memory and accelerate inference. However, existing methods cannot maintain accuracy and hardware efficiency at the same time. We propose SmoothQuant, a training-free, accuracy-preserving, and general-purpose post-training quantization (PTQ) solution to enable 8-bit weight, 8-bit activation (W8A8) quantization for LLMs. Based on the fact that weights are easy to quantize while activations are not, SmoothQuant smooths the activation outliers by offline migrating the quantization difficulty from activations to weights with a mathematically equivalent transformation. SmoothQuant enables an INT8 quantization of both weights and activations for all the matrix multiplications in LLMs, including OPT, BLOOM, GLM, MT-NLG, and LLaMA families. We demonstrate up to 1.56x speedup and 2x memory reduction for LLMs with negligible loss in accuracy. SmoothQuant enables serving 530B LLM within a single node. Our work offers a turn-key solution that reduces hardware costs and democratizes LLMs.




@InProceedings{xiao2023smoothquant,
title = {{S}mooth{Q}uant: Accurate and Efficient Post-Training Quantization for Large Language Models},
author = {Xiao, Guangxuan and Lin, Ji and Seznec, Mickael and Wu, Hao and Demouth, Julien and Han, Song},
booktitle = {Proceedings of the 40th International Conference on Machine Learning},
year = {2023}
}
We thank MIT-IBM Watson AI Lab, MIT AI Hardware Program, Amazon and MIT Science Hub, NVIDIA Academic Partnership Award, Qualcomm Innovation Fellowship, Microsoft Turing Academic Program, and NSF for supporting this research. We thank Haotian Tang, Aohan Zeng, Eric Lin, and Jilei Hou for the helpful discussions.





{kind=link}