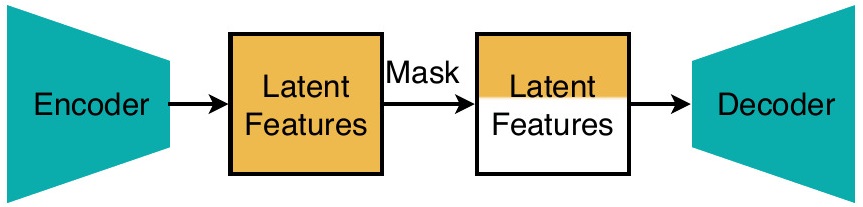
We present DC-AE 1.5, a new family of deep compression autoencoders to accelerate diffusion model convergence with structured latent space.
VILA is a visual language model (VLM) pre-trained with interleaved image-text data at scale, enabling multi-image VLM. VILA is deployable on the edge.
Differentiable augmentation to improve the data efficiency of GAN training.