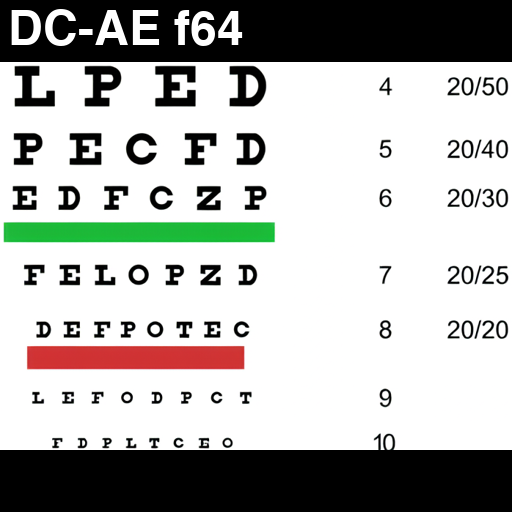
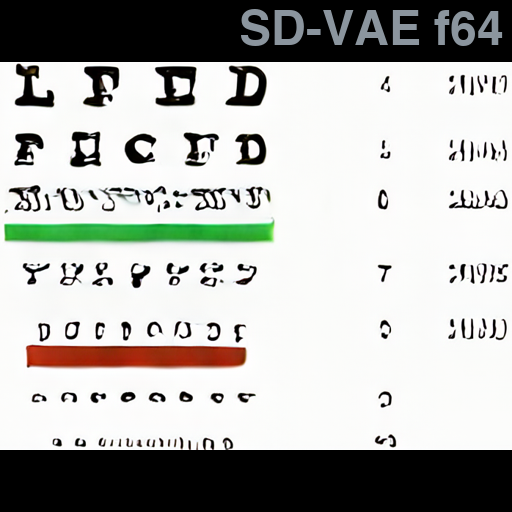
We present Deep Compression Autoencoder (DC-AE), a new family of autoencoder models for accelerating high-resolution diffusion models. Existing autoencoder models have demonstrated impressive results at a moderate spatial compression ratio (e.g., 8x), but fail to maintain satisfactory reconstruction accuracy for high spatial compression ratios (e.g., 64x). We address this challenge by introducing two key techniques: (1) Residual Autoencoding, where we design our models to learn residuals based on the space-to-channel transformed features to alleviate the optimization difficulty of high spatial-compression autoencoders; (2) Decoupled High-Resolution Adaptation, an efficient decoupled three-phases training strategy for mitigating the generalization penalty of high spatial-compression autoencoders. With these designs, we improve the autoencoder's spatial compression ratio up to 128 while maintaining the reconstruction quality. Applying our DC-AE to latent diffusion models, we achieve significant speedup without accuracy drop. For example, on ImageNet 512x512, our DC-AE provides 19.1x inference speedup and 17.9x training speedup on H100 GPU for UViT-H while achieving a better FID, compared with the widely used SD-VAE-f8 autoencoder.







@article{chen2024deep,
title={Deep Compression Autoencoder for Efficient High-Resolution Diffusion Models},
author={Chen, Junyu and Cai, Han and Chen, Junsong and Xie, Enze and Yang, Shang and Tang, Haotian and Li, Muyang and Lu, Yao and Han, Song},
journal={arXiv preprint arXiv:2410.10733},
year={2024}
}
We thank NVIDIA for donating the DGX machines. We thank MIT-IBM Watson AI Lab, MIT and Amazon Science Hub, MIT AI Hardware Program, and National Science Foundation for supporting this research.



