Our work StreamingLLM is covered by MIT News as spotlight!
StreamingLLM is integrated by HPC-AI Tech SwiftInfer to support infinite input length for LLM inference.
StreamingLLM is integrated into NVIDIA TensorRT-LLM!
StreamingLLM is integrated by CMU, UW, and OctoAI, enabling endless and efficient LLM generation on iPhone!
Attention Sink is integrated by HuggingFace Transformers' main branch.
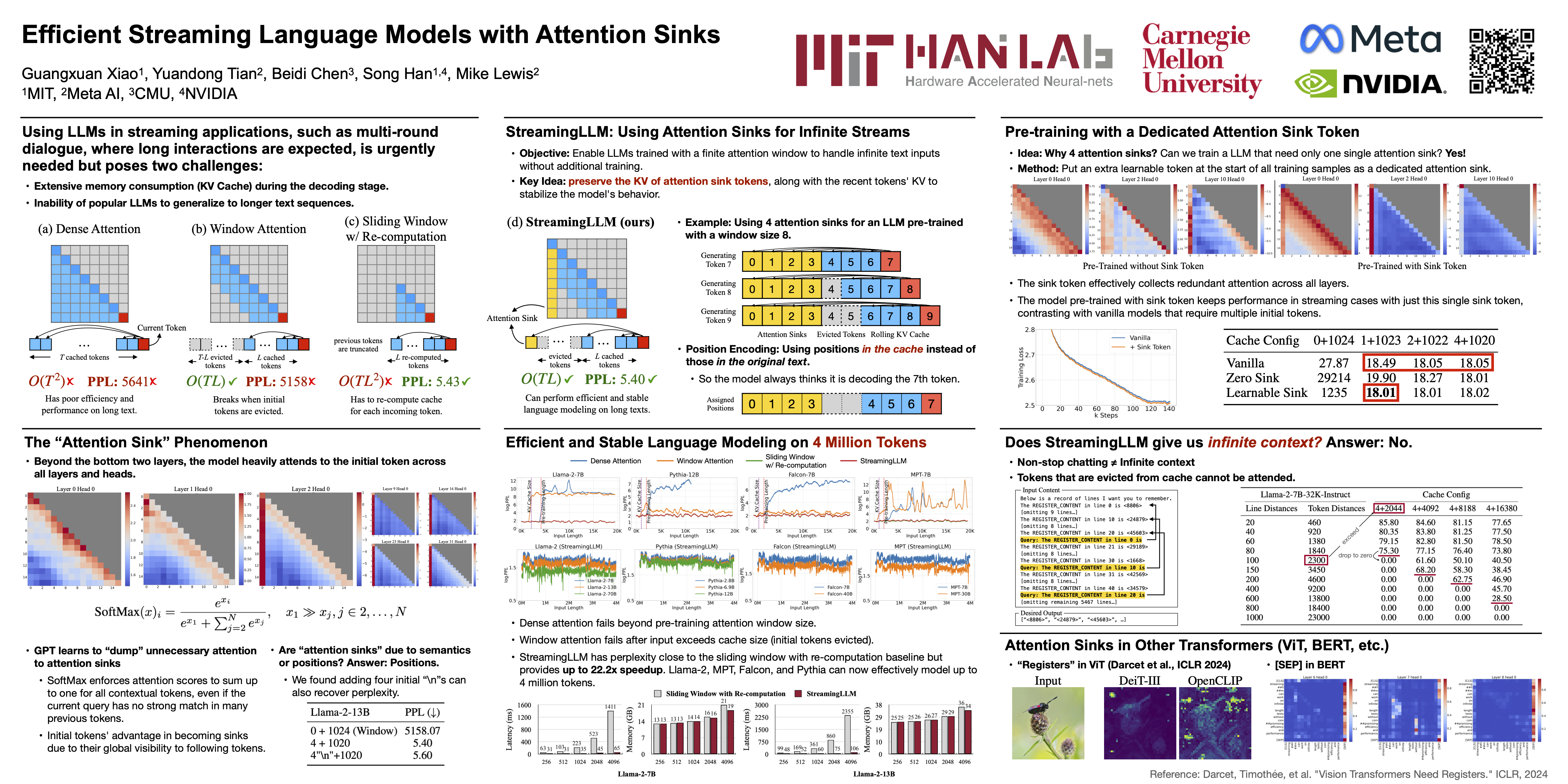
Deploying Large Language Models (LLMs) in streaming applications such as multi-round dialogue, where long interactions are expected, is urgently needed but poses two major challenges. Firstly, during the decoding stage, caching previous tokens' Key and Value states (KV) consumes extensive memory. Secondly, popular LLMs cannot generalize to longer texts than the training sequence length. Window attention, where only the most recent KVs are cached, is a natural approach --- but we show that it fails when the text length surpasses the cache size. We observe an interesting phenomenon, namely attention sink, that keeping the KV of initial tokens will largely recover the performance of window attention. In this paper, we first demonstrate that the emergence of attention sink is due to the strong attention scores towards initial tokens as a ``sink'' even if they are not semantically important. Based on the above analysis, we introduce StreamingLLM, an efficient framework that enables LLMs trained with a finite length attention window to generalize to infinite sequence length without any fine-tuning. We show that StreamingLLM can enable Llama-2, MPT, Falcon, and Pythia to perform stable and efficient language modeling with up to 4 million tokens and more. In addition, we discover that adding a placeholder token as a dedicated attention sink during pre-training can further improve streaming deployment. In streaming settings, StreamingLLM outperforms the sliding window recomputation baseline by up to 22.2x speedup.
Deploying Large Language Models (LLMs) in streaming applications such as multi-round dialogue, where long interactions are expected, is urgently needed but poses two major challenges. Firstly, during the decoding stage, caching previous tokens' Key and Value states (KV) consumes extensive memory. Secondly, popular LLMs cannot generalize to longer texts than the training sequence length. StreamingLLM employs "attention sinks" to extend the processing capabilities of LLMs to infinite text lengths without additional training.
Traditional methods of managing language models in streaming applications face two pivotal challenges:
To better understand these challenges, consider the figure below, which compares the performance of different attention mechanisms as text length increases.

In traditional models, the first token often receives a disproportionate amount of attention—dubbed an "attention sink." This phenomenon arises because the SoftMax function, used in calculating attention scores, ensures that these scores sum up to one across all tokens. When many tokens aren't strongly relevant to the context, the model still needs to "dump" attention somewhere—often on the first token, simply because it's globally visible from any point in the sequence. This recognition leads to an essential strategy in StreamingLLM: always retain the attention sink tokens in the key-value (KV) cache.

StreamingLLM introduces a straightforward yet effective recipe for managing LLMs in streaming contexts:

StreamingLLM shows remarkable stability and efficiency:


Further, StreamingLLM provides a considerable speedup on hardware implementations, such as NVIDIA’s TRT-LLM and mobile devices like the iPhone. The longer the input, the more pronounced the efficiency gains—showing StreamingLLM’s scalability and practicality.
@article{xiao2023streamingllm,
title={Efficient Streaming Language Models with Attention Sinks},
author={Xiao, Guangxuan and Tian, Yuandong and Chen, Beidi and Han, Song and Lewis, Mike},
journal={ICLR},
year={2024}
}






{kind=link}