November 28, 2022
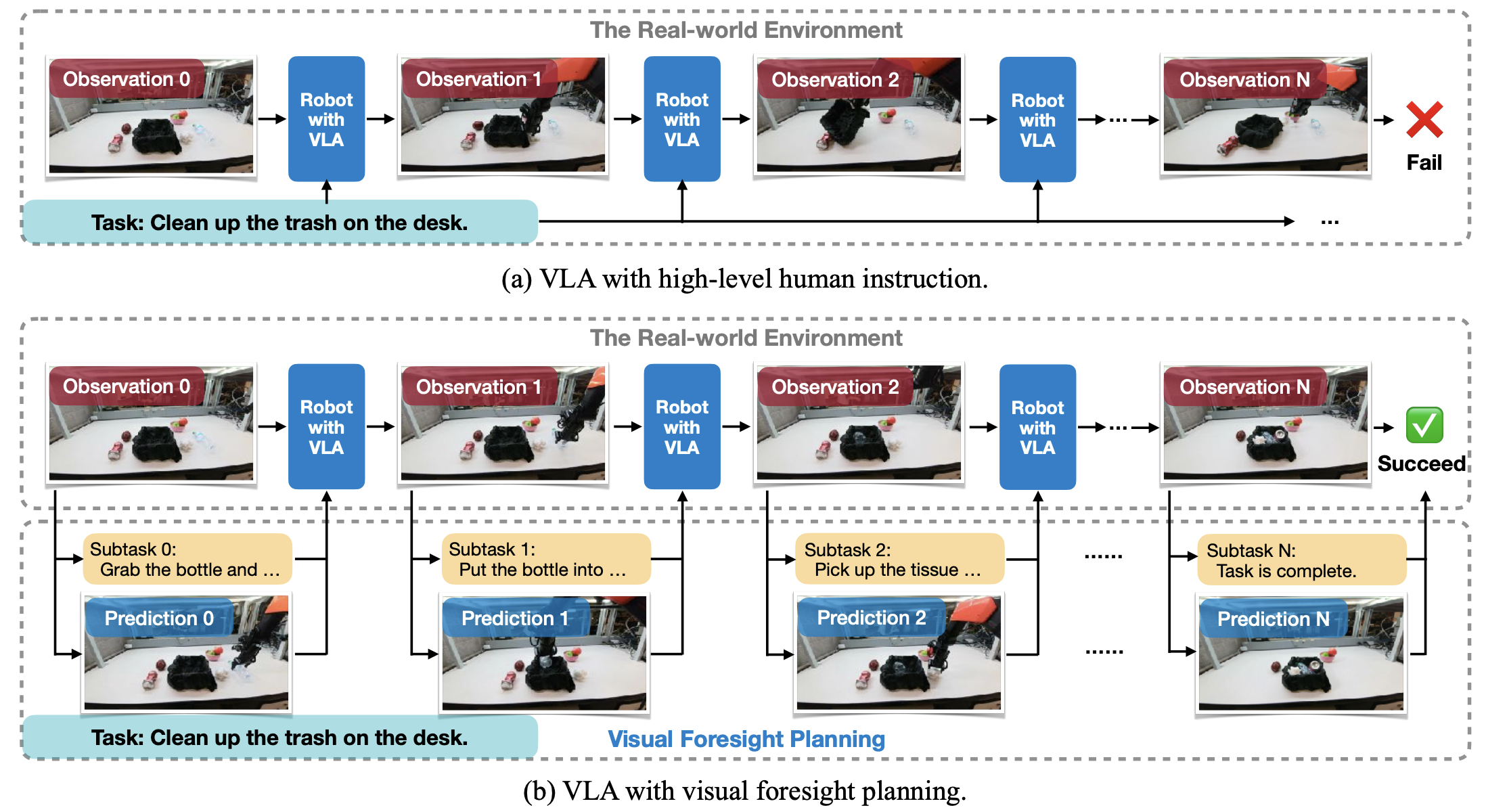
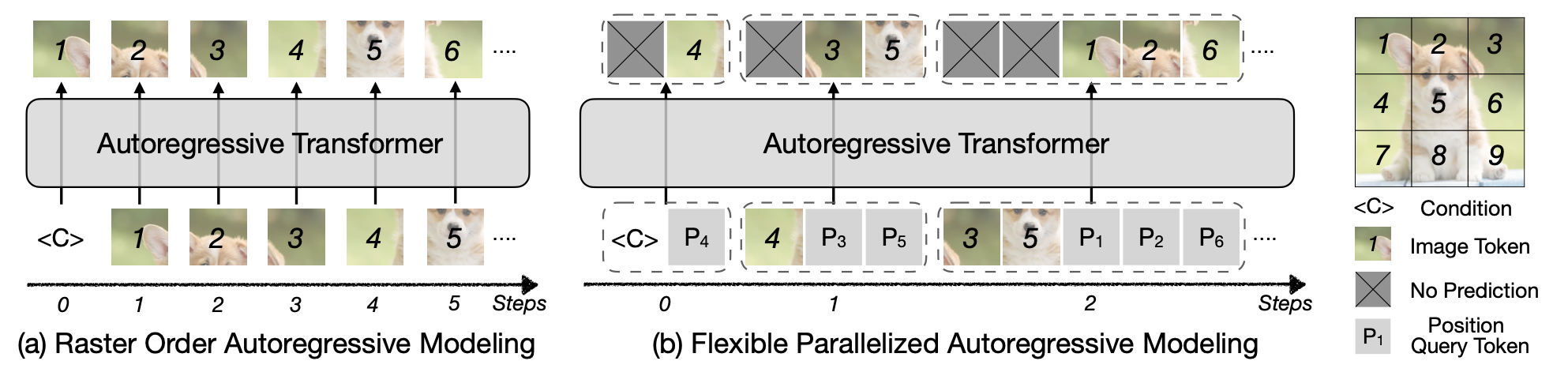
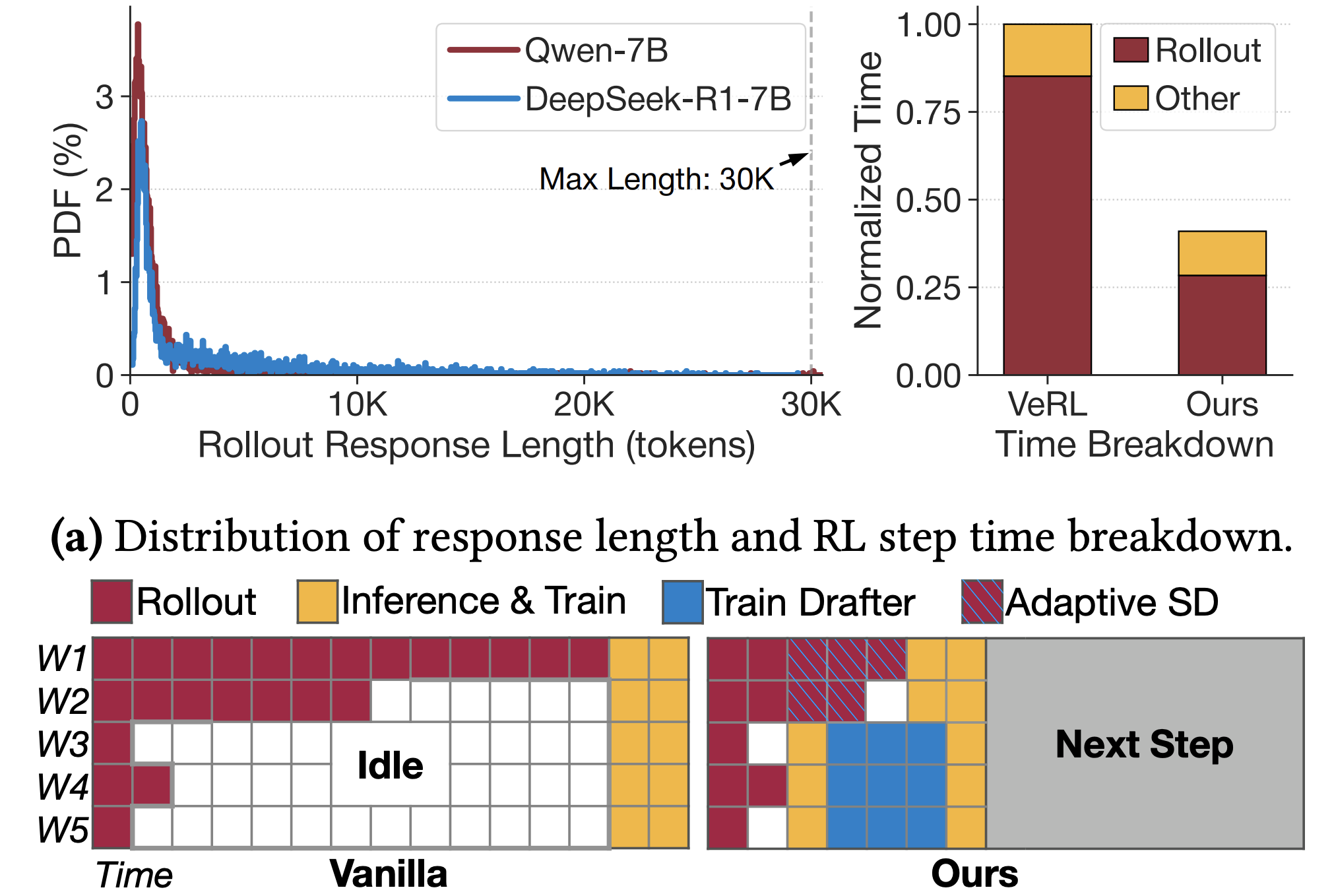
In MCUNetV3, we enable on-device training under 256KB SRAM and 1MB Flash, using less than 1/1000 memory of PyTorch while matching the accuracy on the visual wake words application. It enables the model to adapt to newly collected sensor data and users can enjoy customized services without uploading the data to the cloud thus protecting privacy.