Welcome to MIT HAN Lab, where efficiency meets performance, innovation converges with excellence in the realm of artificial intelligence (AI) and computer architecture. Our lab stands at the forefront of cutting-edge research, encompassing a wide spectrum of topics from LLM and genAI to TinyML and hardware design. Combining expertise in algorithm and hardware, we are dedicated to pushing the limits of efficiency in AI.
Accelerating LLM and Generative AI [slides]:





We show SmoothQuant can enable W8A8 quantization for Llama-1/2, Falcon, Mistral, and Mixtral models with negligible loss.
We supported VILA Vision Languague Models in AWQ & TinyChat! Check our latest demos with multi-image inputs!
Congrats Ji Lin completed and defended his PhD thesis: "Efficient Deep Learning Computing: From TinyML to Large Language Model". Ji joined OpenAI after graduation.
AWQ is integrate by NVIDIA TensorRT-LLM, can fit Falcon-180B on a single H200GPU with INT4 AWQ, and 6.7x faster Llama-70B over A100.
Attention Sinks, an library from community enables StreamingLLM on more Huggingface LLMs. blog.
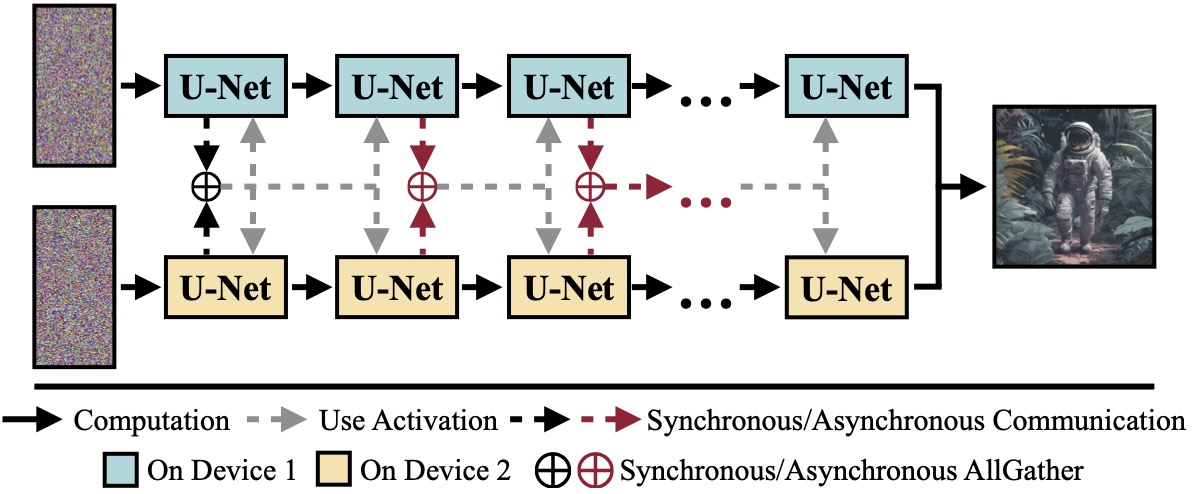
Diffusion models have achieved great success in synthesizing high-quality images. However, generating high-resolution images with diffusion models is still challenging due to the enormous computational costs, resulting in a prohibitive latency for interactive applications. In this paper, we propose DistriFusion to tackle this problem by leveraging parallelism across multiple GPUs. Our method splits the model input into multiple patches and assigns each patch to a GPU. However, naïvely implementing such an algorithm breaks the interaction between patches and loses fidelity, while incorporating such an interaction will incur tremendous communication overhead. To overcome this dilemma, we observe the high similarity between the input from adjacent diffusion steps and propose displaced patch parallelism which takes advantage of the sequential nature of the diffusion process by reusing the pre-computed feature maps from the previous timestep to provide context for the current step. Therefore, our method supports asynchronous communication, which can be pipelined by computation. Extensive experiments show that our method can be applied to recent Stable Diffusion XL with no quality degradation and achieve up to a 6.1× speedup on eight NVIDIA A100s compared to one. Our code is publicly available at https://github.com/mit-han-lab/distrifuser.
A training-free algorithm to harness multiple GPUs to accelerate diffusion model inference without sacrificing image quality.

Visual language models (VLMs) rapidly progressed with the recent success of large language models. There have been growing efforts on visual instruction tuning to extend the LLM with visual inputs, but lacks an in-depth study of the visual language pre-training process, where the model learns to perform joint modeling on both modalities. In this work, we examine the design options for VLM pre-training by augmenting LLM towards VLM through step-by-step controllable comparisons. We introduce three main findings: (1) freezing LLMs during pre-training can achieve decent zero-shot performance, but lack in-context learning capability, which requires unfreezing the LLM; (2) interleaved pre-training data is beneficial whereas image-text pairs alone are not optimal; (3) re-blending text-only instruction data to image-text data during instruction fine-tuning not only remedies the degradation of text-only tasks, but also boosts VLM task accuracy. With an enhanced pre-training recipe we build VILA, a Visual Language model family that consistently outperforms the state-of-the-art models, e.g., LLaVA-1.5, across main benchmarks without bells and whistles. Multi-modal pre-training also helps unveil appealing properties of VILA, including multi-image reasoning, enhanced in-context learning, and better world knowledge.
VILA is a visual language model (VLM) pre-trained with interleaved image-text data at scale, enabling multi-image VLM. VILA is deployable on the edge.

We present Condition-Aware Neural Network (CAN), a new method for adding control to image generative models. In parallel to prior conditional control methods, CAN controls the image generation process by dynamically manipulating the weight of the neural network. This is achieved by introducing a condition-aware weight generation module that generates conditional weight for convolution/linear layers based on the input condition. We test CAN on class-conditional image generation on ImageNet and text-to-image generation on COCO. CAN consistently delivers significant improvements for diffusion transformer models, including DiT and UViT. In particular, CAN combined with EfficientViT (CaT) achieves 2.78 FID on ImageNet 512x512, surpassing DiT-XL/2 while requiring 52x fewer MACs per sampling step.
A new conditional control method for diffusion models by dynamically adapting their weight.
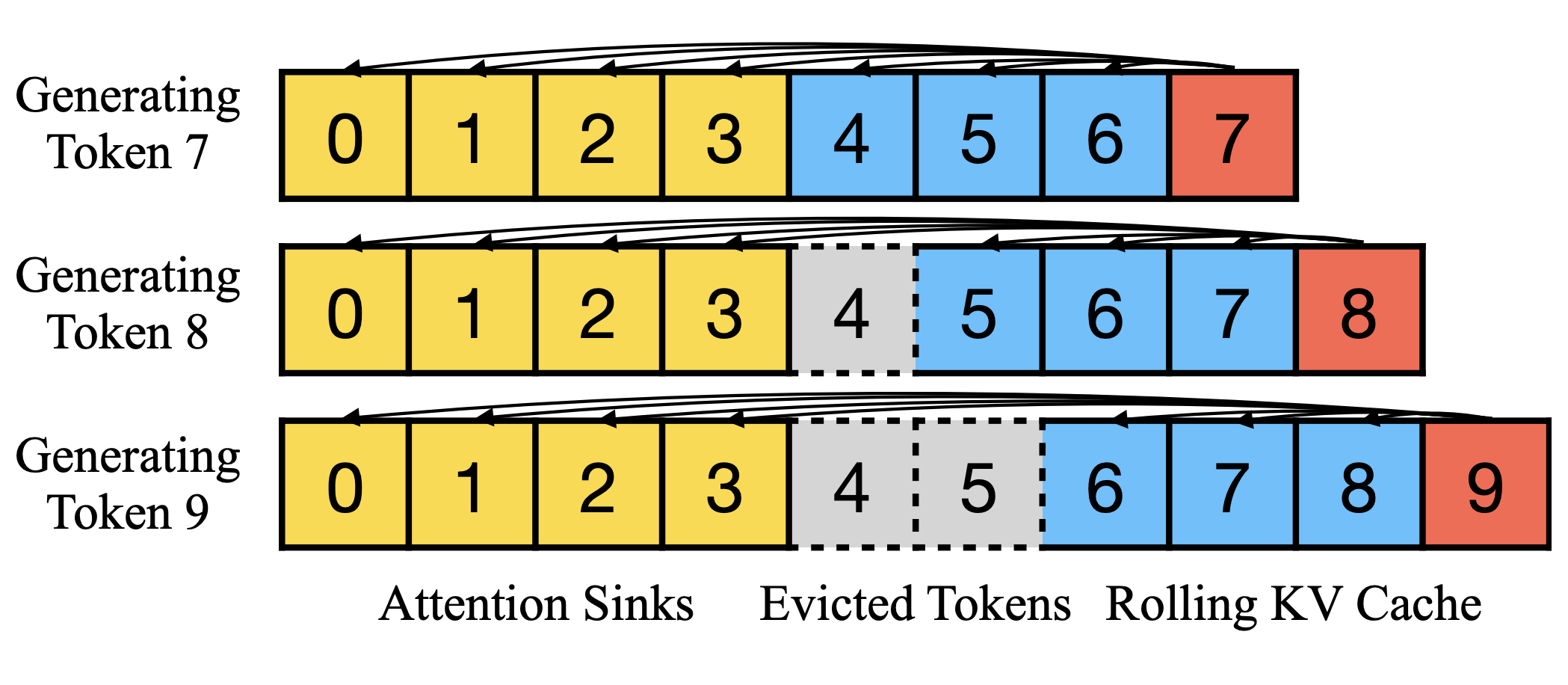
Deploying Large Language Models (LLMs) in streaming applications such as multi-round dialogue, where long interactions are expected, is urgently needed but poses two major challenges. Firstly, during the decoding stage, caching previous tokens' Key and Value states (KV) consumes extensive memory. Secondly, popular LLMs cannot generalize to longer texts than the training sequence length. Window attention, where only the most recent KVs are cached, is a natural approach --- but we show that it fails when the text length surpasses the cache size. We observe an interesting phenomenon, namely attention sink, that keeping the KV of initial tokens will largely recover the performance of window attention. In this paper, we first demonstrate that the emergence of attention sink is due to the strong attention scores towards initial tokens as a ``sink'' even if they are not semantically important. Based on the above analysis, we introduce StreamingLLM, an efficient framework that enables LLMs trained with a finite length attention window to generalize to infinite sequence length without any fine-tuning. We show that StreamingLLM can enable Llama-2, MPT, Falcon, and Pythia to perform stable and efficient language modeling with up to 4 million tokens and more. In addition, we discover that adding a placeholder token as a dedicated attention sink during pre-training can further improve streaming deployment. In streaming settings, StreamingLLM outperforms the sliding window recomputation baseline by up to 22.2x speedup.
We enable LLMs to work on infinite-length texts without compromising efficiency and performance.
We actively collaborate with industry partners on efficient AI, model compression and acceleration. Our research has influenced and landed in many industrial products: Intel OpenVino, Intel Neural Network Distiller, Intel Neural Compressor, Apple Neural Engine, NVIDIA Sparse Tensor Core, NVIDIA TensorRT LLM, AMD-Xilinx Vitis AI, Qualcomm AI Model Efficiency Toolkit (AIMET), Amazon AutoGluon, Facebook PyTorch, Microsoft NNI, SONY Neural Architecture Search Library, SONY Model Compression Toolkit, ADI MAX78000/MAX78002 Model Training and Synthesis Tool.






















